









Abstract
Fashion image editing aims to edit an input image to obtain richer or distinct visual clothing matching effects. Existing global fashion image editing methods are difficult to achieve rich outfit combination effects while local fashion image editing is more in line with the needs of diverse and personalized outfit matching. The local editing techniques typically depend on text and auxiliary modalities (e.g., human poses, human keypoints, garment sketches, etc.) for image manipulation, where the auxiliary modalities essentially assist in locating the editing region. Since these auxiliary modalities usually involve additional efforts in practical application scenarios, text-driven fashion image editing shows high flexibility. In this paper, we propose TexFit, a Text-driven Fashion image Editing method using diffusion models, which performs the local image editing only with the easily accessible text. Our approach employs a text-based editing region location module to predict precise editing region in the fashion image. Then, we take the predicted region as the generation condition of diffusion models together with the text prompt to achieve precise local editing of fashion images while keeping the rest part intact. In addition, previous fashion datasets usually focus on global description, lacking local descriptive information that can guide the precise local editing. Therefore, we develop a new DFMM-Spotlight dataset by using region extraction and attribute combination strategies. It focuses locally on clothes and accessories, enabling local editing with text input. Experimental results on the DFMM-Spotlight dataset demonstrate the effectiveness of our model.
Method
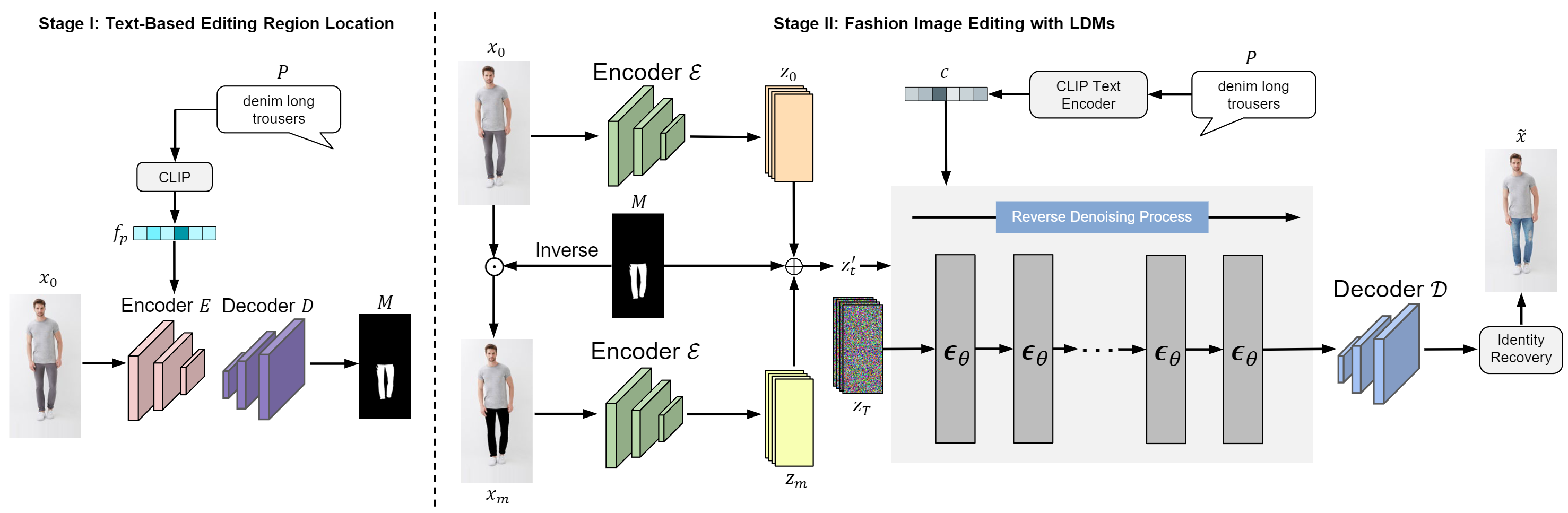
Overview of our TexFit. We divide the entire editing process into two stages. In the first stage, we locate the editing region in the fashion image based on the text prompt, and then in the second stage we employ LDMs to precisely edit the visual content within the editing region of the fashion image.
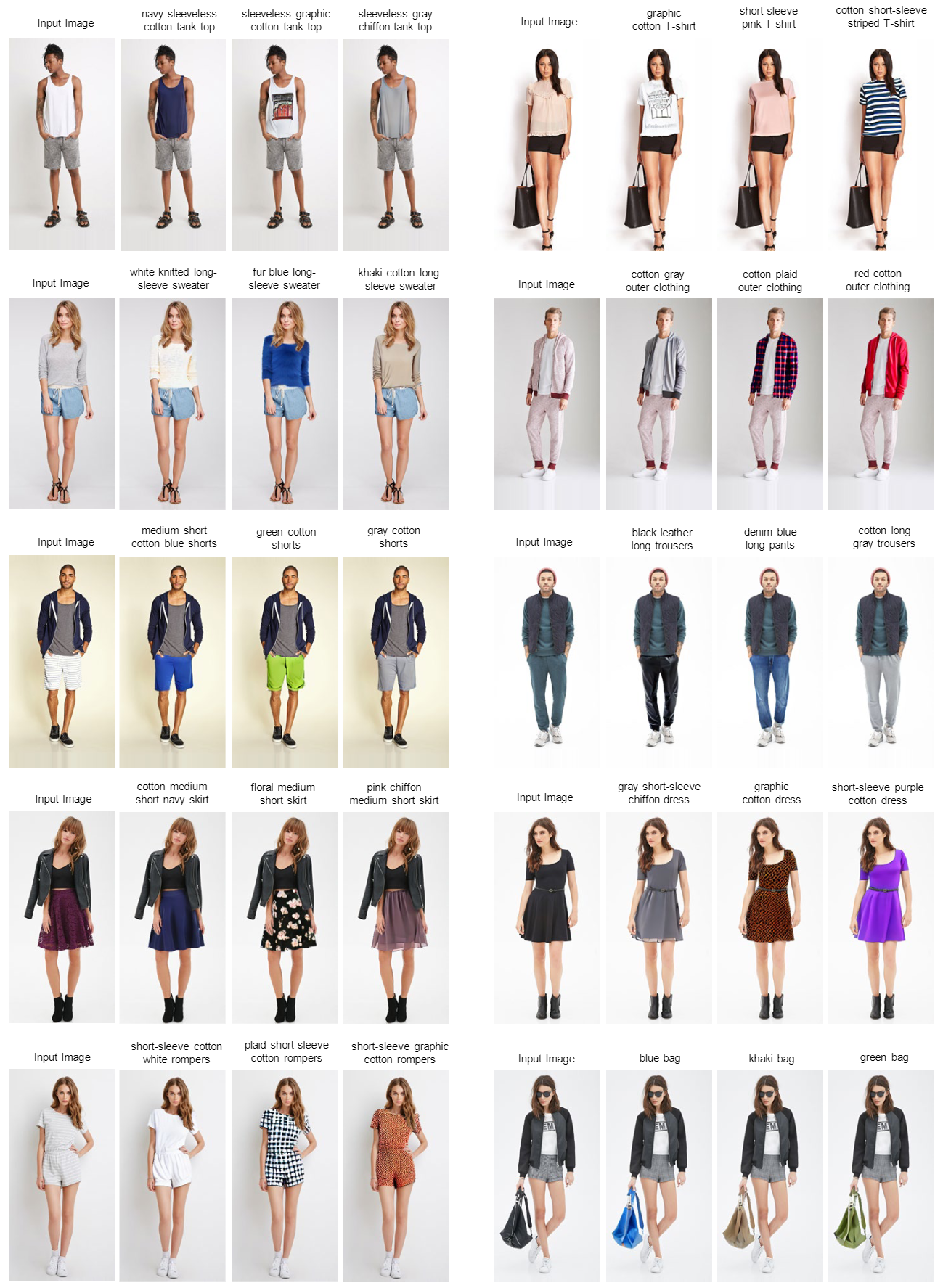
Additional Results
Bibtex